Oracle Fusion Middleware customers use Oracle Service Bus (OSB) for virtualizing Service endpoints and implementing stateless service orchestrations. Behind the performance and speed of OSB, there are a couple of key design implementations that can affect application performance and behavior under heavy load. One of the heavily used feature in OSB is the Service Callout pipeline action for message enrichment and invoking multiple services as part of one single orchestration. Overuse of this feature, without understanding its internal implementation, can lead to serious problems.
This post will delve into OSB internals, the problem associated with usage of Service Callout under high loads, diagnosing it via thread dump and heap dump analysis using tools like
ThreadLogicand OQL (Object Query Language) and resolving it. The first section in the series will mainly cover the threading model used internally by OSB for implementing Route Vs. Service Callouts.
OSB Pipeline actions for Service Invocations
A Proxy is the inbound portion of OSB that can handle the incoming request, transform/validate/enrich/manipulate the payload before invoking co-located or remote services. The execution logic is built using the proxy pipeline actions. For executing the remote (or even local) business service, OSB provides three forms of service invocations within a Proxy pipeline:
- Route - invoke a single business service endpoint with (or without) a response. This happens entirely at end of a proxy service pipeline execution and bridges the request and response pipeline. The route can be treated as the logical destination to reach or final service invocation. There can be only one Route action (there can be choices of Route actions - but only one actual execution) in a given Proxy execution.
- Publish - invoke a business service without waiting for result or response (like 1-way). The caller does not care much about the response. Just interested in sending out something (and ensuring it reaches the other side).
- Service Callout - invoke one or more business service(s) as part of message augmentation or enrichment or validation but this is not the primary business service for a given Proxy, unlike the Route action. The service callouts can be equivalent to credit card validation, address verification while Route is equivalent to final order placement. There can be multiple Service Callouts inside a Proxy pipeline.
OSB Route Action
Most HTTP remote service invocations with responses are synchronous and blocking in nature. The caller creates a payload, connects to the business service endpoint, transmits the payload and waits for a response. The caller has to wait till the response is ready and transmitted back. Using Java Native IO, one can avoid the blocking wait for response and only read the response once its ready. But this is not an easy option for higher level applications that aim at SOAP, XML, REST forms of service interactions. They need threads to wait for the response and if the remote business services are slow, more threads can get tied up instead of working on other tasks.
When using the Route Action for HTTP based Business services, OSB does not tie up a thread waiting for the remote response. Instead it leverages Native IO within WebLogic Server Muxer Layer and
Future Response AsyncServlet functionality to decouple the caller thread from the actual response handling portion thereby behaving asynchronously. When the client makes a request to OSB Proxy and the request pipeline finally executes a Route action, OSB posts the request one-way and registers a future Response Async Servlet method to receive a callback of the response.
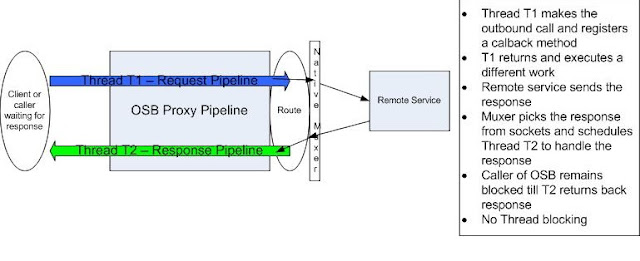
The proxy thread that processed the request pipeline path makes the outbound call and returns, without waiting for the actual response. This thread is then free to execute other pending requests. The WLS Muxer layer detects when there is response data readily available to be read from the socket for that outbound business service call and then triggers a callback to the OSB's registered Async Servlet. Now a different thread picks the response and then execute the response pipeline flow within OSB. This way, the proxy uses two threads for segregating the request from the response processing in the Route Action. This translates to OSB using minimal threads for service executions, without blocking for response, even if the remote service is slow. But for the external client calling into OSB, it appears like one synchronous blocking call, while OSB keeps its thread usage to the minimum and handles more requests, without using additional threads or waiting for remote service responses.
By default, for most HTTP based interactions for both incoming Proxy service and external Route, there would be no transactions involved and so the Route action would use Best-Effort QoS (Quality of Service) and would leverage the async threading model described previously. However, if the Route is invoked as part of an existing transaction (if the calling Proxy service was JMS with XA Connection Factory enabled or other Transactional proxy service invocation like Tuxedo or started off a Transaction in the middle of the pipeline) and wants to use Exactly-Once QoS, then the invoking Thread (T1) of the Route action blocks till a response is received and then commits the transaction. The response is only then picked by another thread (T2) after the Route action is completely successful and transaction committed. So, the thread invoking Route will appear as blocking. If the QoS is changed to Best-Effort, then the async threading model will be used as in case of HTTP based service invocations.
OSB Service Callout Action
A Service Callout is not the actual target or end service for a Proxy Service in OSB. Its simply a service invocation to either modify, validate, transform, augment or enrich the incoming request or outgoing response within a proxy execution. It can be invoked from either the request or response path. Multiple Service Callouts can also be executed in any order or fashion. Route is the final target and so there can only be one route in a proxy execution. Service callouts are used when a response is needed from the service execution. So, the caller of the Service Callout will block till a response is available. If responses are not needed or its strictly one-way sends, Publish Action can be used.
Most users will consider the OSB Service Callout to be similar to Route action. Both are invoking some remote service and ultimately getting back some response. The caller of the proxy blocks till the response is received. The time used by the remote service in sending back the response cannot be cut down from the final proxy response time. But the request and response handling part differs considerably in the Service Callout compared to the Route Action.
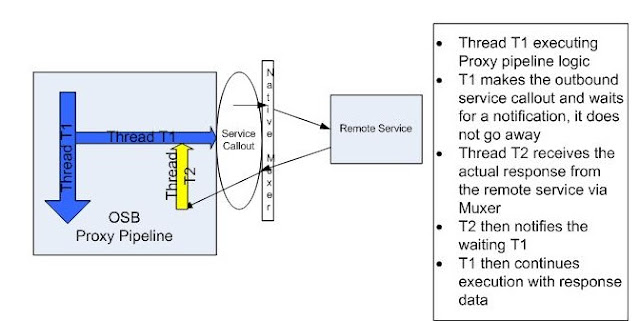
Unlike in Route where the invoking thread returns right away after making the remote invocation, the Service Callout thread T1 actually waits for a notification of response for that invocation; it does not really handle the response directly from the remote service. When the remote service sends back a response, the WLS native Muxer layer picks it and then schedules another thread T2 to handle it. The thread T2 does not really do much other than notify the waiting T1 thread of the availability of response and return. Now T1 wakes up from its waiting state and then continues execution of the rest of the proxy pipeline logic. So, in case of Service Callout, the original thread T1 actually waits for the response to become available, while another thread T2 is needed to pick the response and then notifies T1. So, essentially two threads will be used with one thread (T1) completed dedicated for duration of the service callout and beyond and another thread for a short while. In Route, threads T1 and T2 are never used concurrently and also, are not wasted or needed, when the response is yet to be sent across from the remote service.
This design implementation of Service Callout action can affect the behavior of OSB under high loads when there is heavy use of Service Callouts to either aggregate data from multiple services or just used repeatedly for VERT (Validate, Enrich, Route, Transform) messages instead of using Routing action. As more requests repeatedly use Service callouts, these can tie up valuable threads waiting for the response from remote or other local services while there are no more threads available to handle the actual incoming response and notify the waiting Service callout threads. In summary, overuse of Service callouts can lead to thread starvation issues and degraded performance under heavy loads.
For a synchronous publish (like Exactly-Once QoS Publish) that has to wait for confirmation and response, the behavior is the same as in Service Callout - requires two threads for the waiting and notification.
Summary
Hope this post gave some pointers on the internal implementation of OSB for Route Vs. Service Callouts and correct usage of Service Callouts. The remaining sections will deal with identifying issues with callouts using Thread Dump and Heap Dump Analysis and the corrective actions to resolve them







{kind=link}